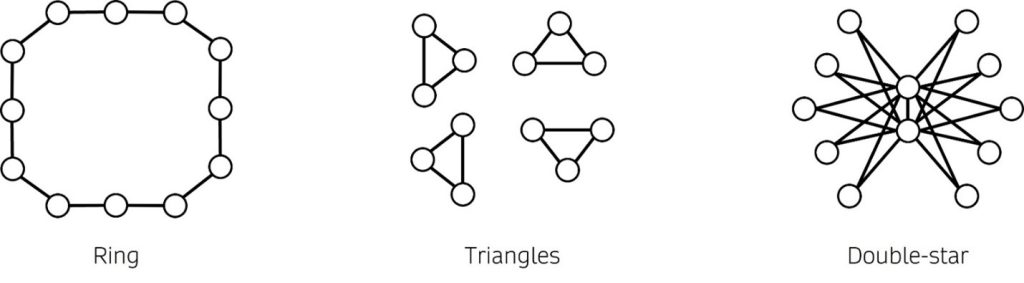
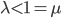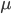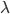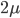Waiting in a queue is boring, but the mathematical theory of queues can be fascinating. This article discusses a fun puzzle that illustrates a beautiful open problem in this area: queueing theorists are trying to figure out how the structure of a network impacts its ability to distribute work among the nodes. While this is a very difficult problem, we might be able to at least tell them which of the networks in Figure 1 is better.
Which network is beter?
Figure 1. Three different networks.
From supermarkets to data centers
If you have visited different supermarkets, then you have probably noticed that customers can be distributed across the various checkout counters in different ways. While in some stores customers wait in a single queue until one of the counters becomes available, there are also supermarkets with a dedicated queue for each checkout counter. If you do not like waiting in a line, then you may wonder if one of these two store layouts helps to reduce the waiting time of customers. The answer is yes!
To answer the question, it might be easier to think about the total amount of time that the counters are idle, since it is clearly inefficient to have a free counter and a customer that is waiting in some line at the same time. If we have a single queue for all the counters, then customers will not wait in the queue unless all counters are busy. But with dedicated queues for each counter, it is possible that several customers will be queueing in front of a busy counter while another counter is free in the opposite corner of the store. The single queue layout is thus more efficient, and it can be proved that this leads to shorter waiting times.
Then why do some stores have parallel queues in front of each counter instead of just one central queue? One of the reasons is that in a large supermarket some of the checkout points can be far away from the head of the central queue. Thus, it can take minutes to walk from the head of the central queue to the checkout counter that is the furthest away. Also, it can be easier to accommodate relatively short queues in front of each counter than one longer central queue, particularly in supermarkets, where it is desirable to use most of the surface of the supermarket to exhibit as many products as possible.
While incredibly large and complex, data centers behave to some extent in the same way as supermarkets. The checkout counters of these digital factories are computers called servers, which are stacked in multiple rows that fill long corridors, and customers do not come directly but send service requests over the internet; examples of the tasks that servers execute are webpage retrieval, social media posting and online shopping transactions. For technological reasons, data centers have dedicated queues at each server as in large supermarkets. In a supermarket customers select the queue that they will join, but data centers have special devices, called dispatchers, for selecting the queue where each task will be placed; these are like the queue managers at airports who tell passengers which security checkpoint they should use. The time that tasks remain in the data center until they are completed heavily depends on how the dispatchers assign tasks to servers. The algorithms that the dispatchers use to make this assignment are called load balancing algorithms.
Load balancing in a network of servers
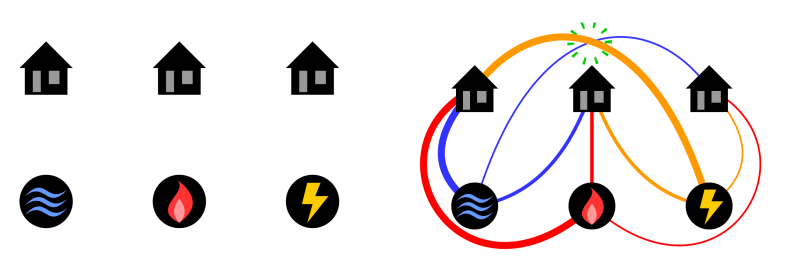
Another difference between supermarkets and data centers is that queues in a supermarket are exchangeable, because customers can pay at any counter, whereas queues in a data center may not be exchangeable for various reasons. One of these reasons is that executing certain tasks can require some prestored data that is only available at certain servers; for example, streaming applications can only store a small fraction of their huge catalog of movies at each of the servers. Another reason is that data centers may require multiple dispatchers, as only one dispatcher may not be able to handle all the service requests, which creates multiple entry points for the tasks.
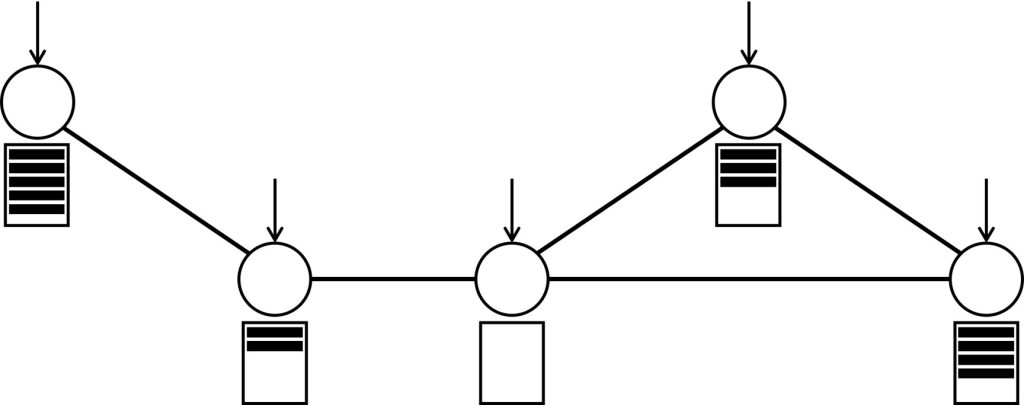
Figure 2. A network of servers with dedicated queues.
Real data centers are too complex to be analyzed mathematically, so mathematicians create stylized models that capture some key features of data centers and allow to obtain some useful insights. One such model is depicted in Figure 2. Here servers and their queues are placed at the nodes of a network. Also, each server acts as a dispatcher, receiving tasks over time and deciding in which queue each task should be placed. The network represents assignment constraints which reflect that the servers are not exchangeable; a given server cannot send tasks to any other server. In particular, a task can only be placed in one of the queues in the neighborhood of the server that initially receives the task; the neighborhood consists of this server itself and all the servers that are directly connected by an edge. Let us assume that the server that receives the task always makes the natural choice: to dispatch the task to the shortest queue in the neighborhood. Can you guess which of the networks of Figure 1 makes it easier to distribute the tasks evenly across the servers?
Which network is beter?
Mathematicians know that networks with larger neighborhoods can help to distribute tasks across the servers better. Intuitively, larger neighborhoods offer more choices for dispatching tasks. But other structural properties of the network also matter.
In all the networks of Figure 1, most of the neighborhoods have three servers; in the Ring and the Triangles all the neighborhoods are of size three, whereas the Double-star only has two neighborhoods that are larger. However, these networks have striking structural differences. For example, the Ring and the Double-star are connected since we can move between any pair of servers without leaving the network. In contrast, the Triangles are disconnected, which seems rather inconvenient if we want to distribute work among all the servers. Furthermore, in some sense the Double-star is more connected than the Ring since we can move between any two servers in at most two steps, while in the Ring we may need to visit half of the servers; think about passing the salt around the table from one extreme to the other.
The seemingly superior connectivity of the Double-star suggests that it is the best network. But surprisingly, it turns out that the Double-star is actually the worst network!
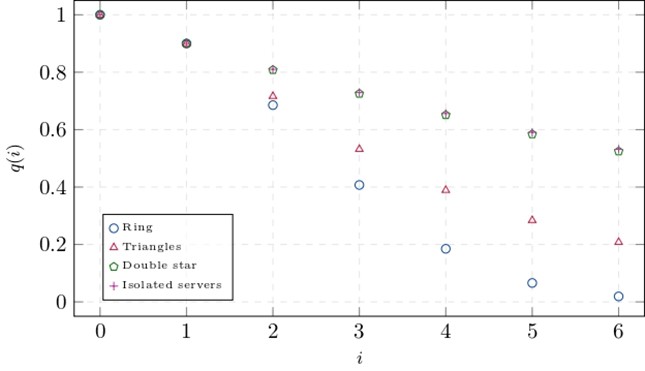
Figure 3. Load balancing in the networks of Figure 1.
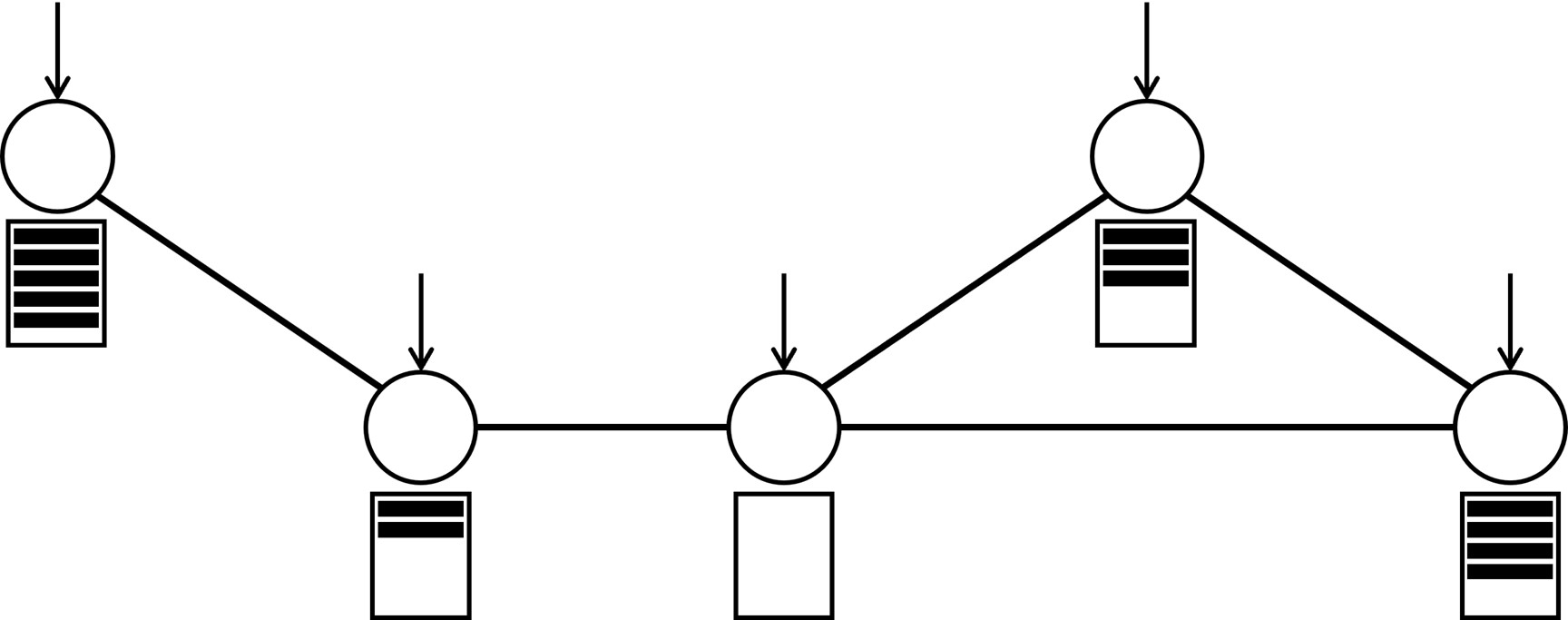
Figure 3 indicates how each of the three networks performs. The figure shows the fraction (or percentage) of queues that have at least tasks for each possible ; for example, note that in all the cases since all the queues have always at least zero tasks. If is smaller for all , then the network is clearly better. Moreover, it is possible to prove that the sum of over all possible is proportional to the average amount of time that tasks wait until finished. The plot shows that the Ring is better than the Triangles, as expected, and it reveals that the Double-star is the worst network. In fact, the plot indicates that the Double-star is nearly as bad as a fully disconnected network where all servers are isolated. All the neighborhoods of this network consist of exactly one isolated server, and when a task arrives at any server, the only possible choice is to place the task in the queue of this server.
But why is the Double-star so bad? The reason is that the two central servers get saturated, rendering this seemingly highly connected network disconnected, as if the central servers did not exist. In other words, most of the time the central servers are buried under large piles of tasks while the great majority of the outer servers have fewer tasks. When a task arrives at an outer server, the central servers usually have more tasks, and since the only neighbors of this outer server are the central servers, the new task is placed in the queue of the outer server. Because all but two of the servers are outer servers, the fraction of servers with at least tasks is nearly equal to the fraction of outer servers with at least tasks, and these servers act as if they were isolated, placing all the tasks in their own queues.
This requires thinking about the speed or rate at which tasks arrive to and are executed by the servers. Throughout the article we have implicitly assumed that at each server tasks arrive at a rate that is lower than the processing rate of the servers, otherwise the total number of tasks grows without bounds over time. Let us assume that tasks arrive at each server at rate and that each server executes tasks at rate . The neighborhood of the central servers is the entire network. Thus, if a task arrives at any server and the number of tasks at the server is larger than the number of tasks at one of the central servers, then the task is sent to one of the central servers. As a result, tasks are placed in one of the central queues at a rate that is at least times the number of servers that have more tasks than the central servers. While this quantity remains larger than the processing rate of the central servers, the number of tasks at the central queues tends to increase over time and the number of servers with more tasks than the central servers tends to decrease. However, at a certain point the rate at which tasks are placed at the central queues stabilizes around the processing rate , and this implies that the number of queues with more tasks than the central servers must remain small after this point in time.
Now we know that the Ring is the best of the networks of Figure 1 and that the Double-star is the worst. Moreover, we have learned that large neighborhoods are not always beneficial. In fact, networks like the Double-star where servers with large neighborhoods are surrounded by poorly connected servers can behave as if the highly connected servers did not exist, rendering the network much less connected than it seems.
We still do not fully understand how the structure of a network impacts its ability to distribute tasks across the servers. However, the puzzle that we have solved illustrates a key fact: mathematicians have observed that network structure is not that relevant when all the neighborhoods are large, but the puzzle shows that network structure really matters in networks that have small neighborhoods!
What if I tell you that long queues in airports are also caused by the impatient passengers that arrive too far in advance at the airport? Today, we will analyze how the organization of the security check queue affects the waiting time of passengers.
Imagine you’re in a remote village and only have a limited number of vaccines to distribute to protect the community from a deadly virus, who do you vaccinate?
A difficult decision, but necessary. Assuming that the disease is just as deadly for everyone in the community, the best way to prevent deaths is to contain the spread of the virus.
Applications of machine learning models are everywhere, with many online platforms and major science fields using tools relying on machine learning. Take, for example, image recognition and computer vision. But did you know that the results of supposedly perfect and accurate machine learning models can be deceived by slight perturbations in the data?
In this article Maya continues her journey from Rotterdam to Brussels. She starts thinking about a puzzle from her childhood, the three utilities problem. At the end of the jouney she has reached a very important theorem from graph theory!
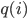 (or percentage) of queues that have at least
(or percentage) of queues that have at least 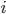 tasks for each possible
tasks for each possible 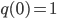 in all the cases since all the queues have always at least zero tasks. If
in all the cases since all the queues have always at least zero tasks. If 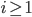 is proportional to the average amount of time that tasks wait until finished. The plot shows that the Ring is better than the Triangles, as expected, and it reveals that the Double-star is the worst network. In fact, the plot indicates that the Double-star is nearly as bad as a fully disconnected network where all servers are isolated. All the neighborhoods of this network consist of exactly one isolated server, and when a task arrives at any server, the only possible choice is to place the task in the queue of this server.
is proportional to the average amount of time that tasks wait until finished. The plot shows that the Ring is better than the Triangles, as expected, and it reveals that the Double-star is the worst network. In fact, the plot indicates that the Double-star is nearly as bad as a fully disconnected network where all servers are isolated. All the neighborhoods of this network consist of exactly one isolated server, and when a task arrives at any server, the only possible choice is to place the task in the queue of this server.