You wake up in the morning, and reach out to your smartphone to cancel the alarm and check up on the latest developments on social media. You decide to go for an early-morning run, during which your smartwatch tells you to run faster to increase your heartbeat. Then, at work, you make your laptop work almost as hard as you do yourself. When you’ve returned home, you make your way to this article on the Network Pages. Finally, after the long day has passed, your video gaming console is there for some much needed relaxing.
In our daily lives, we use a lot of electronic devices. Each of these are essentially computers, in that they perform a lot of computations. These devices process the tasks we set them, such as ‘sync my e-mail’, ‘measure my heartbeat’, ‘load this article’ and so on. Only a few decades ago, the only digital devices we ever used were big desktop computers. These computers processed tasks one after another, in the order we set them. It worked, nice and simple, and that was it.
An illustration made by Alex Nazlidis for the Network Pages
Today, we demand much more from our devices and we take for granted that they all work nice and fast. Without realizing, we usually greatly value a speedy processing of our tasks. To you, whether your e-mail is synced in 0.2 or 2 seconds probably does not make much of a difference. However, for other things, such a difference can be huge. For example, if you’re playing a video game and you are lagging 2 seconds behind, instead of just 0.2 seconds, you probably will not have much fun. And it is not just video gaming… think for example also of a long-distance Skype-call with a friend, or automatic trading on the financial markets.
Speed is thus of the essence, but how do current-day devices cope with this? The answer: your devices can multi-task.
Your devices can multi-task!
To understand how your devices can multi-task, let us take a look at the inside of these devices. Your devices have chips inside them, which do the computational work. These days, such chips typically consist of multiple cores. These cores are units that can process tasks independently from one another.
To illustrate, it is quite likely that the chip of your laptop has at least four cores. This means that your laptop can process four tasks in parallel: one core for syncing your e-mail, another to play a video, etc. This number can get much higher too; 256 cores in a remote server is not unheard of.
But there is also another way of using all your cores. Current-day tasks are designed such that they can also be processed on multiple cores at once. In other words, a task can for example be ‘split into four parts’, so that all four cores can work together on a single task!
Parallel computing and its (dis)advantages
This latter way of multi-tasking, parallel computing, can speed up things tremendously, provided that tasks are split up in the right number of parts. Or in other words, parallelized across the right number of cores. Deciding what the right number is, is not as easy as it may seem. First off, you’d expect that if all four cores of your laptop are working on your task, the task is completed four times as fast. However, this is not the case; its so-called speedup could be just three times. This is because the task needs to be split up between cores, which takes some time. Next to this, it could be that some parts of the job simply cannot be split between cores that easily.
To illustrate, imagine that you and your friends want to play a card game with a huge deck of cards. To shuffle these cards efficiently, you can decide to have your friends help by giving each of them a part of the deck to shuffle. This can indeed speed up things. But the speedup will never be perfect: you need to split up your deck into parts, which takes a little time. Additionally, when all parts are shuffled, you will still have to give each of your friends a hand of cards, which is something that cannot be efficiently sped up. This works the same way in parallel computing, making it in some sense inefficient in its efficiency!
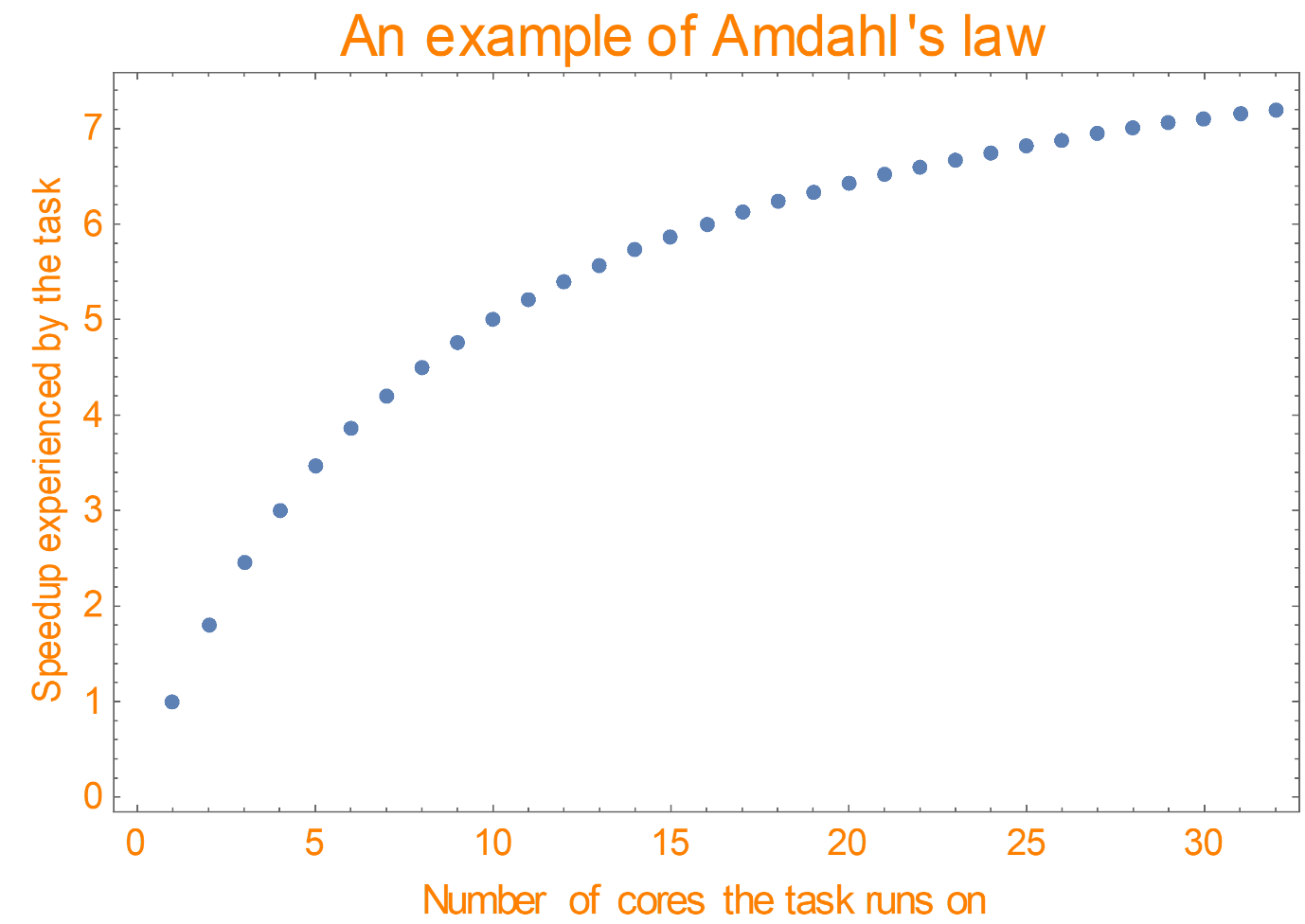
This effect was already noted in the 1960s by the computer scientist Gene Amdahl (see [1]). His Amdahl’s law below describes what a speedup could look like when a task is allocated a certain number of cores.
Amdahl’s law in the figure above for example says that by computing parallelly, a speedup of 7 and more can be reached if enough cores are available. This means that a task that would otherwise take two seconds on a single core can be processed within 2/7 seconds: this is great! It however also demonstrates the above-mentioned effect: if the task runs on 4 cores, it will run only 3 times as fast. The figure does not show a straight line, but a curve which eventually flattens.
Let us now look through the eyes of a task for a moment, and think of the question ‘As a task, on how many cores would we like to run, if it were up to us?’. Based on the figure, we would see that claiming a fourth core does not speed up things much more beyond the case where we would only claim three cores.
Nevertheless, the fourth core still speeds up things up by a little. Hence, through the eyes of a task there is no reason not to claim it. When given the opportunity, tasks would claim all cores available. In other words, they are greedy. This greediness may lead to problems, as we will now see.
Parallelisation for the Network Pages
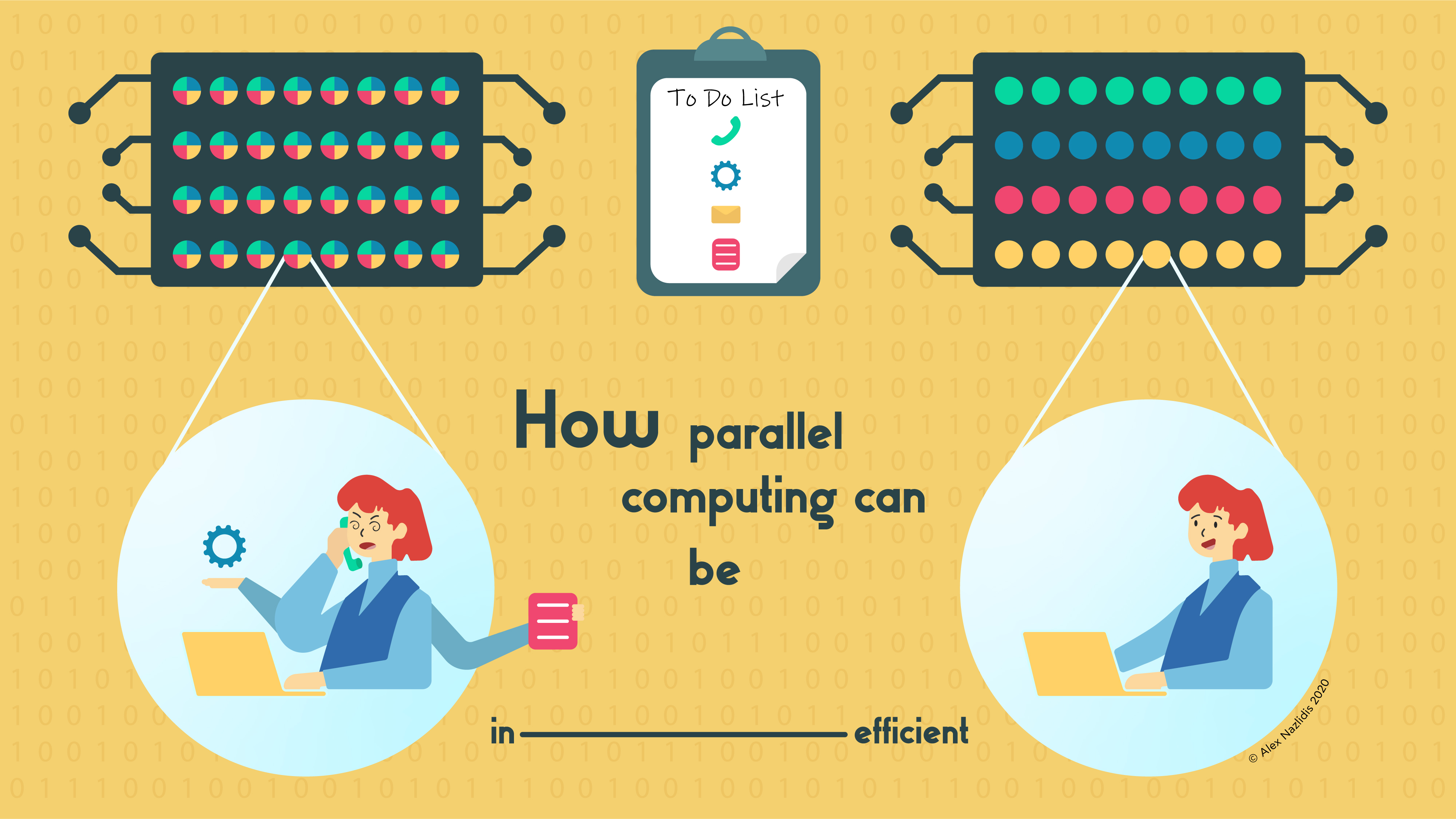
Think of the internet server of the Network Pages which you’re reading right now. When browsing to this article, you unknowingly send a task to the internet server, requesting this article. Suppose that this internet server has 32 cores, and that your task can be split up to run on multiple cores.
Your task, greedy as it is, would claim all 32 cores to deliver you this article as fast as possible. Due to Amdahl’s law, this won’t lead to the article loading 32 times faster compared to the case where only one core is used. Still, looking at the figure, you’d expect that this parallelisation would speed up things by roughly 7 times (7.2 times to be precise).
But, suppose now that three other persons requested this article at the same time as you did. Then we have four tasks, each of which wants to claim all 32 cores. Imagine the situation: each task has been split up in 32 parts. However, since all four persons want to read this article, each core is presented with four task parts. The cores will process all of these parts at the same time. In other words, because each core now divides its attention across all four persons trying to read this article, your speedup will now not be 7.2, but 7.2/4 = 1.8.
An illustration made by Alex Nazlidis for the Network Pages.
Something just does not feel right. Your task gets split up in 32 parts, while no part actually gets the full attention of any core. Therefore, the speedup can probably be made even better. It is reasonable to ask: is this the best way to go? Should tasks really decide how many cores to run on? Or is the speedup then indeed not optimal? And if that’s the case, what should we do then?
The answer is a definite and an unequivocal no. We should not let tasks decide what to do. Instead, our devices should decide how to assign jobs to cores.
For example, in the example of the internet server, it would be better if the server would provide each of the tasks just 32/4 = 8 cores each. A task then only needs to be split up in eight parts, rather than 32 of them. Also, each core gives its full attention to its (part of the) task. As a result, according to our figure, the speedup for each task will be 4.5, which is much better than the 7.2/4 = 1.8 before!
This example shows that parallel computing has great potential, provided that it is used correctly. Much scientific research, such as the paper of [2], is devoted to this topic. Many more questions remain, such as what to do if a fifth person browses to the Network Pages, while the four tasks are already halfway done? With the help of math, this research aims at making and keeping your devices work as fast as possible. This way, your alarm will go off at the right time tomorrow morning, you can safely go for a run, and by the end of the day, your video game will run as smoothly as you can imagine.
If, after reading the title, your immediate response is to shout "1/6-th", then you have correctly answered the question. Well done! However, in this article we will focus on the meaning of this question. What exactly is this "chance" of which you've just exclaimed it equals 1/6-th?
Are you one of those people who always seems to pack just a bit too much for your car to handle when packing for a vacation? Then you should have a look at this article!
During our teenage years, everything changes. It’s no surprise that our brain does too. But how do we make sense of this transformation? Is there a way to quantify it? Networks might just be the answer.
We want our guts to be filled with a diverse range of mutually beneficial and competitive interactions, a perfect blend of friends, frenemies, and enemies to keep our guts active and body on its toes. Read how networks can help understand these interactions!