Birgit Sollie is a PhD student at the VU Amsterdam, where she does research in stochastic processes and mathematical biology. In this interview she talks about her research and her motivation for doing mathematics.
When were you first interested in math?
I always liked math in high school and I was good at it. But my first choice was to study engineering. That turned out not to work for me. Because I also really liked the mathematics courses, hence I switched to mathematics.
A good choice?
Hell yes. After the first year I immediately realized that I was in the right place. I really enjoyed seeing the abstraction of mathematics, and the applicability of mathematics in so many different areas.
And did you soon know that you wanted to continue with research after your studies?
In the second year of my master I started thinking about what I wanted after my studies. At that time, I had the feeling that I had not finished learning yet, and that I also wanted to continue with mathematics at a high level. Both are possible in a PhD, so I decided to go for it!
What is your research actually about?
My research is about stochastic population processes. For example, you can think of the growth or shrinkage of an animal population, or of the fluctuations in the number of molecules in a cell. My research focuses specifically on population processes where there is also a background process that influences population growth. For example, climate or nature can act as a background process that influences the growth of an animal population. Similarly, the growth of molecules can be influenced by temperature.
My research looks at these population processes at an abstract level as a two-dimensional process: the growth process, combined with the background process.
And what do you want to learn about these population processes?
In my research, we estimate the parameters of the population processes restricted by the fact we cannot observe the background process. The latter makes it very difficult from a mathematical point of view. Even though we cannot observe the background process, it does affect your observations. For example, you cannot just set up a likelihood and determine maximum likelihood estimators. But this also makes it interesting: by just observing the population number, we can still estimate all parameters of both the population process and the background process!
Can you also test these estimators on real data?
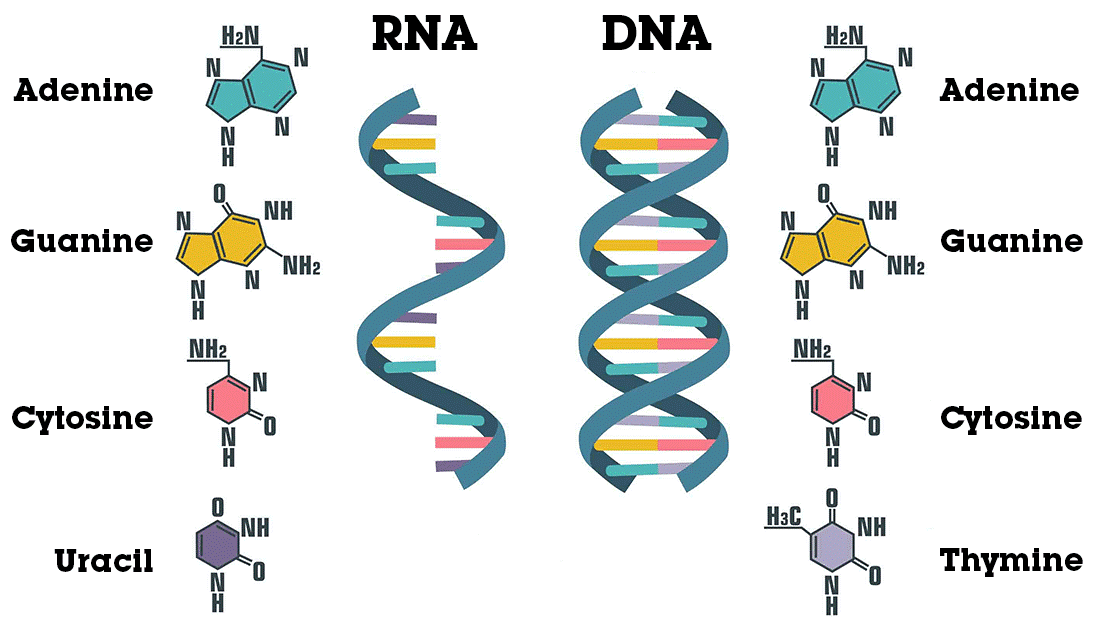
In simulations, we can test whether our estimators work on data that we have made by ourselves, and this shows that our methods do indeed work. Now I'm working on the next step: see how our estimators fare on real data on the number of RNA molecules in cells. The background process is then a combination of many different factors, such as the temperature of the cell. All of these factors are controlled by your cells, and they determine whether the production of RNA will go up or down. It would be nice if we could extract this background process from the data with my estimators. The first results already look very promising.
What do you think is the most interesting problem you have been working on in recent times?
A while ago we investigated what happens when individuals in a population can move across a network, but you can't see how they move. This adds yet another level of difficulty in conjunction with the unobservable background process. Even then we can estimate all parameters of the population process and the background process. I found this a very nice challenge myself.
What result are you most proud of?
I am not necessarily more or less proud of my different results. Still, I think the publication of your first paper is always the most special.
Is there another big challenge you would like to explore later?
Until now I have mainly estimated parameters of models. But I think it would also be very interesting to apply non-parametric estimation methods. Then you do not estimate parameters of a model, but you estimate, for example, an entire probability distribution. We now often assume that processes are exponential, and then we only need to estimate the parameter of the exponential process. This assumption is very useful from a mathematical point of view, but of course not always realistic. It is also possible that, for example, the mortality in your population does not follow an exponential distribution. The question then is: can we estimate the entire distribution of the mortality process?
And in the area of application?
It would also be nice to focus more on the application. Now I am mainly concerned with the abstract process that can describe many different applications. I also think it would be interesting to focus more on specific biological applications. For example, I think that my research can also be applied very well to infectious diseases.
In addition to your research, you also sometimes give presentations to high school students about mathematics. What do you like or important about this?
Mathematics is applicable to so many different areas, and it can be seen everywhere. I didn't realize this at all in high school, while that's the great thing about math. So I really enjoy showing this to high school or college students, hopefully to get them interested in math.
You were also a member of EWM-NL.
At EWM, for example, I was involved in the mentor network. Here, women in mathematics can apply for a mentor: a more experienced mathematician researcher. This mentor is someone from outside your university or department, whom you can meet from time to time to discuss questions or problems you encounter.
You can describe the growth of the number of RNA molecules using a population-process.
Finally: what do you like or dislike about doing research?
I really like that you always keep learning and can continue to do math at a high level. What I do think is a shame is that you often do research alone. You do have collaborations, but you do most of your research behind your own desk. That is why I like that you can alternate your research with teaching, in order to also have that interaction with students.
Last January I was very pleased to attend an annual summer school in discrete mathematics in Valparaíso, Chile. It was the very first time for me to attend such a summer school overseas as a master’s student. It was a wonderful journey, especially when discussing mathematics.
On a quiet afternoon, professor Meth is working in her office in Leiden on some tantalizing mathematics problems. Suddenly, someone knocking on her door nervously disrupts the silence.
Claudia Flandoli is an author of comics and an illustrator, with a keen interest in science topics. Last year she gave a short talk during the opening of IMAGINARY in Amsterdam. We couldn't let this opportunity pass and we asked her for an interview about art and science.
In November 2024, the Kick-Off meeting for BeyondTheEdge: Higher-Order Networks and Dynamics took place at Vrije Universiteit (VU) Amsterdam. The event marked the official start of the project, read an interview with Christian Bick, Principal Investigator and Project Coordinator of BeyondtheEdge.