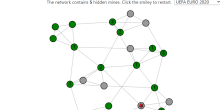
Common sense tells us that objects of comparable size should be equally hard to find. Yet, when searching inside a random network, surprises are awaiting . . .
Networks, especially such of a social nature, surround us: we are part of our family, our network of acquaintances and work colleagues, but also of Twitter or LinkedIn. From an individual point of view, the most important part of a network is formed by those that are closest to us. A good friend of mine likes to wear T-shirts showing his kung fu club’s logo on all kinds of occasions. My mother has exactly the same decorative wooden bird in her bathroom as her friends. And I am sure that you have your own examples.
Large and tightly interconnected subgroups are very influential within a network. Generally, the more tightly an individual is connected within the network, the more it is affected by group standards. From the point of view of a policy maker or marketing agent, it is thus desirable to identify such groups, especially in networks with a large number of individuals. To think about this problem in a structured way, it is useful to identify the main theoretical aspects of a network: Basically, a network is composed of individuals that form relationships, or links, with each other.
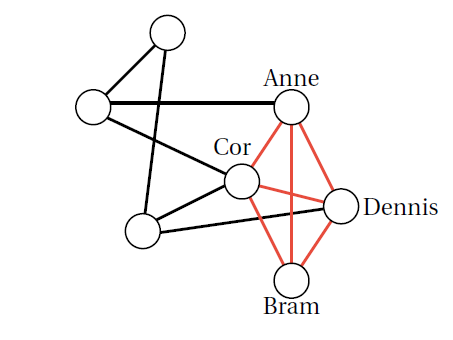
The largest clique in the network: Anne, Bram, Cor, and Dennis.
Again, in such an abstract network, we can speak about tightly connected subgroups. Conveniently, these subgroups are called cliques:
A mathematical clique is a sub-network in which every member is in relation to every other member – like in your clique of friends in high school.
This abstract framework facilitates an analysis of our original more pragmatic question: How would you practically find a large clique in a huge network?
Searching all possible networks
Without a clever approach, this requires an extensive search through the network. Since this will presumably take a very long time, surely, you would want to delegate this task to a computer (or a PhD student, which you might not have at hand). Still, you need to give the computer a manual in form of a set of rules that it can follow to find the cliques. We call such a set of rules an algorithm.
Ideally, this algorithm would be reasonably fast: the time that you wait for the output of the largest clique in the network should scale nicely in relation to the network size. For example, one thing that we aim to avoid not only in Covid reproduction numbers, but also in terms of waiting time, is exponential growth, since it is a very fast type of growth. A slower type of growth is given by polynomial growth, and in this line, we call an algorithm fast if the search time scales polynomially with the network size.
To solve your problem, in the above jargon, all that is missing is thus a fast algorithm that solves the problem of finding a largest clique in any given network.
Unfortunately, until today, nobody has ever been able to come up with such an algorithm! Even worse, already in 1972, computer scientist and Turing Award winner Richard Karp showed in a mathematically precise sense that our “clique problem” is truly hard to solve. The argument is based on a comparison of the clique problem to other problems for which no fast algorithms are known: If you succeed to find a fast algorithm for one of them, then you can transfer it to solve all of the others.
Richard M. Karp. By Rama - Own work, CC BY-SA 2.0 fr, Wikipedia.
To add more bad news to an already dark picture, by now it is known that it is also difficult to find cliques that are substantially smaller than the largest clique of a given network! For example, no fast algorithm is known that always succeeds in finding a clique that is only half as big as the largest clique of the network.
Searching the average network
While these proofs of difficulty provide an explanation as to why no one ever has found a fast algorithm for the clique problem, they only consider algorithms that work well on all networks, without a single exception. Maybe this is not really necessary, and there still is a possibility to find the largest or nearly largest cliques in most networks in a fast way. This is a general idea in such problems: When finding an answer for all possible networks seems too much to ask, you ask for the existence of a slightly smaller, but still almost exhaustive class of networks that is manageable, to keep the question interesting and worth answering.
To answer the latter question, we would have to look at all networks with the same number of individuals simultaneously and find out for which proportion of them a given algorithm works – a rather overwhelming task. Luckily, through a more probabilistic lens, we can reduce this question to the study of just a single network; even though a random one. The idea is the following: For a given number of individuals, say like in "number", let us assume that each possible network with individuals is equally likely to be presented to us for a study of the clique problem. In this experiment, if the probability that an algorithm finds a large clique is close to one, then we can conclude that the probability that it works on a proportion of all networks is also close to one. This may seem abstract to you at the moment, but believe me if I say that this idea hides depth and shows how a different perspective can yield a solution to a problem!
What is more, the typical size of the largest clique in such a random network is known, and thus we have a very clear picture as to what the algorithm should answer: For a random network of size , the typical size of the largest clique is about (in this article denotes the natural logarithm). In a network of the size of the population of Amsterdam (about 822.000), this would be surprisingly small - about 39 individuals! In a network of ten times the size of Amsterdam, this would be about 46 individuals. And because the logarithm grows so slowly in comparison to the overall network size , searching for the largest clique in a typical random network really is a bit like looking for a needle in a haystack.
To add onto the good news, the very same Richard Karp in 1976 crafted a fast algorithm that finds cliques of half-optimum size (or 19 in the example of Amsterdam) for the average network. This is great news, since we have seen above that until today, no one has found an algorithm that achieves the same performance on all networks. You get much more optimistic, and make enquiries about the existence of a fast procedure that actually finds one of the cliques of size , which still hide somewhere in most networks. Also, this question has already been asked by Richard Karp in the very same article where he presented the algorithm that finds cliques of half-optimum size – and is still open.
In a webinar given on this topic, MIT professor David Gamarnik stated the following:
To me, this sounds like the most embarrassing algorithmic problem in random graphs that I can think of. Because we can find a straightforward algorithm to find a clique of half-size. In 1976 Karp challenged to find a better algorithm, and sadly this is still an open problem. This is embarrassing because someone would expect we can do better using more sophisticated algorithms. But these don't seem to work, and nowadays we actually believe that this is a very hard problem.
Now this is truly puzzling. What is the difference between a clique of size and a clique of size - or, in other words, between a needle and half a needle?
The overlap-gap property
At present, there is no complete answer as to why we can find cliques of size in an average network fast, but not of size , say. However, there are several theories. One especially compelling theory is inspired by insights from theoretical physics. The main idea here is to analyse how similar the cliques of a certain size are to each other. In simple words, in the clique problem, you observe a dichotomic behaviour: Any two large enough cliques either share a substantial proportion of their members, or overlap in very few individuals; and nothing in between is likely to happen. In other words, there is a gap.
This is a phenomenon that has been observed in many problems of a similar behaviour, and has been coined the overlap-gap property (or OGP for short) by the mathematician David Gamarnik, while the core notion has been inspired by observations of statistical physicists from around 2005.
Now, why is this a problematic property in terms of algorithms? The existence of a "nice" algorithm that works in the presence of an overlap gap can be led ad absurdum by the following thought experiment. Let us lower the bar a bit and only look for cliques of size , which are very likely to be present in the random network. Also, suppose that there is a candidate algorithm that typically finds cliques of this size for a random network. Finally, suppose that "niceness" of the algorithm means that it is stable with respect to the input, in the sense that if it is presented two networks that only differ in one link, then it outputs very similar large cliques.
We then take two random networks and of the same size . Typically, the cliques of of size have very little in common with the cliques of size of , which is a variant of the OGP looking at two networks. To give a reminder, the OGP said that any two large enough cliques either share a substantial proportion of their members, or overlap in very few individuals. Therefore, the candidate algorithm has to produce a large clique for that is vastly different from the one for .
On the other hand, we can easily transform into , by adjusting one link at a time. Then any two consecutive networks along the way differ by at most one connection. Along the path from to , at any step, the output of the algorithm can only change by a small amount, since it was assumed to be stable. But in the end, it still has to cross the huge distance between the large cliques of and of !
Consequently, no stable algorithm that works on typical networks can exist: If you want to go from Romania to Brazil, you can do a lot of small steps in between, but at some point, you will have to jump over the Atlantic Ocean. Unfortunately, many fast algorithms have the form of stability used in the argument, including powerful quantum algorithms. As a consequence, the OGP excludes a large class of fast algorithms for the largest clique problem.
The largest clique problem is just one of many random optimisation problems which share the same puzzling qualitative behaviour. For such problems, the OGP presents a path towards an explanation of algorithmic hardness through structural properties of near-optimal solutions. Of course, this is no proof that no fast algorithms for these problems exist, and many opportunities for further discoveries remain. After all, truth is more valuable if it takes you a few years (or indeed, decades!) to find it.
In this article, dear reader, I am going to show you in which way the development of your opinion during the last political issue, the spread of a virus among your acquaintances during the current pandemic, and the alignment of some particles lying inside the device from which you are reading this article are extremely comparable phenomena.
How can one hope to understand the precise structure of a virus if it is able to become unrecognizable within weeks? The mathematics behind this questions didn't let go of my mind for extensive periods of time during my PhD studies in Belgium.
If you were born in the previous century, then chances are high that you have spent quite some hours playing Minesweeper, the classic puzzle game that used to be installed on every computer. In this article, we will present a new network-based version of this game and show how network science can help you play this game.
Phenomena like social cohesion and polarisation emerge from individual interactions on the social network of relationships between people. So, what does this network look like?
Back in 2015, I joined the Movember health movement, a movement that you probably have heard of having something related to men growing a moustache. As a woman, you might imagine, I did not join for the moustache thing, but rather for the cause behind the moustache symbol, that is, raising awareness of prostate and testicular cancer.


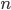 like in "number", let us assume that each possible network with
like in "number", let us assume that each possible network with 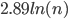 (in this article
(in this article 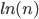 denotes the natural logarithm). In a network of the size of the population of Amsterdam (about 822.000), this would be surprisingly small - about 39 individuals! In a network of ten times the size of Amsterdam, this would be about 46 individuals. And because the logarithm grows so slowly in comparison to the overall network size
denotes the natural logarithm). In a network of the size of the population of Amsterdam (about 822.000), this would be surprisingly small - about 39 individuals! In a network of ten times the size of Amsterdam, this would be about 46 individuals. And because the logarithm grows so slowly in comparison to the overall network size 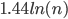 (or 19 in the example of Amsterdam) for the average network. This is great news, since we have seen above that until today, no one has found an algorithm that achieves the same performance on all networks. You get much more optimistic, and make enquiries about the existence of a fast procedure that actually finds one of the cliques of size
(or 19 in the example of Amsterdam) for the average network. This is great news, since we have seen above that until today, no one has found an algorithm that achieves the same performance on all networks. You get much more optimistic, and make enquiries about the existence of a fast procedure that actually finds one of the cliques of size 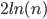 , say. However, there are several theories. One especially compelling theory is inspired by insights from theoretical physics. The main idea here is to analyse how similar the cliques of a certain size are to each other. In simple words, in the clique problem, you observe a dichotomic behaviour: Any two large enough cliques either share a substantial proportion of their members, or overlap in very few individuals; and nothing in between is likely to happen. In other words, there is a gap.
, say. However, there are several theories. One especially compelling theory is inspired by insights from theoretical physics. The main idea here is to analyse how similar the cliques of a certain size are to each other. In simple words, in the clique problem, you observe a dichotomic behaviour: Any two large enough cliques either share a substantial proportion of their members, or overlap in very few individuals; and nothing in between is likely to happen. In other words, there is a gap. 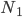 and
and 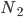 of the same size
of the same size